

The market for cloud-native drug discovery platforms reached USD 3.2 billion in 2025, with 83% of pharma companies using cloud infrastructure. Adoption is settled. The strategic questions are where these platforms accelerate discovery, what structural frictions undermine the investment case, and why data readiness, not platform capability, determines whether investment compounds.
The market for cloud-native drug discovery platforms reached USD 3.2 billion in 2025, with 83% of pharma companies using cloud infrastructure. Adoption is settled. The strategic questions are where these platforms accelerate discovery, what structural frictions undermine the investment case, and why data readiness, not platform capability, determines whether investment compounds.
This figure captures the organisation running a single SaaS application on shared servers alongside the one that has rebuilt its entire discovery stack on cloud-native micro services. It conflates a procurement decision with an architectural one. The more instructive number is 40%, the share of pharma companies that report all operations as fully cloud-operational. There is a 43-point gap between any cloud use and full cloud operation. Investment is concentrating around AI-first drug developers at a pace traditional drug developers have not matched: the $688 million Recursion-Exscientia merger and Isomorphic Labs' $600 million raise both closed within the past eighteen months, against a cloud-native discovery platform market growing at 13.4% annually through 2032. These are well-capitalised companies pursuing their own pipelines while licensing platform access to established pharma, and their commercial interests do not always align with those of the companies they sell to.
The preclinical case for these platforms is strong and well-evidenced. The clinical translation case is not, and the gap between the two is widening as more AI-derived molecules reach Phase 2. Underneath both stories sits a problem most organisations have not resolved: their internal scientific data is not structured, annotated, or accessible enough for the platforms they are buying to do useful work. This article examines where platform value concentrates, what undermines it, and what organisations need to fix before investment generates returns.
The Definitional Problem
The phrase 'cloud-based platform' is used loosely and covers architectures that differ greatly in how much existing infrastructure they replace, how much compliance work they create, and whether their value grows or stalls once deployed. A useful way to think about it is shown in Figure 1, which broadly splits the wide range of platform architectures into three categories. Adoption numbers routinely conflate them: 19 of the top 20 pharmaceutical companies use AWS for generative AI and machine learning. This is a measure of hyperscaler penetration rather than cloud-native maturity.
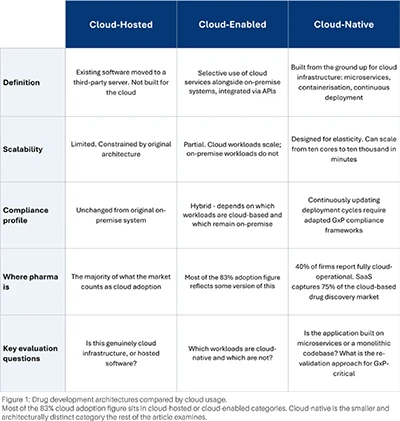
Most of the 83% cloud adoption figure sits in cloud-hosted or cloud-enabled categories. Cloud-native is the smaller and architecturally distinct category the rest of the article examines.
Platform Contribution Across the Drug Development Pipeline
Platform contribution across the pipeline is uneven. It concentrates on the two ends, target identification and post-market, where the data conditions cloud-native platforms depend on are most consistently met. In the middle stages, the data is sparser, the modalities are siloed, and the predictive validity is weaker. Cloud-native compute helps far less here than platform vendor marketing suggests. The pattern shapes how platform investment should be sequenced against competing R&D infrastructure priorities.
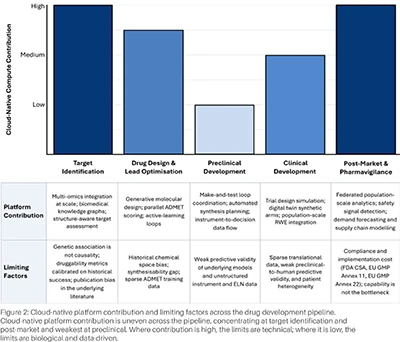
Cloud-native platform contribution is uneven across the pipeline, concentrating at target identification and post-market and weakest at preclinical. Where contribution is high, the limits are technical; where it is low, the limits are biological and data-driven.
At target identification, the cloud-native case is well-evidenced. Cloud-native architecture brings three capabilities into a single analytical layer: multi-omics network graphs combining genomics, transcriptomics, proteomics, biobank phenotypes, and real-world evidence; biomedical large language models tied to biological networks; and knowledge graphs that fold the scientific literature into the same queryable structure. Structure-aware target assessment anchored on AlphaFold3 extends high-accuracy modelling to protein-ligand-RNA complexes and supports blind docking from sequence inputs alone. Insilico's PandaOmics nominated TNIK as the IPF target in a 2024 Nature Biotechnology paper, and the resulting molecule, rentosertib, cleared randomised Phase 2a efficacy in Nature Medicine in June 2025. The field has produced the cleanest two-stage evidentiary chain. Where the data conditions fail, target ID models inherit the gaps. Training data are sparsely populated for novel target classes outside the historical kinase, GPCR, and nuclear-receptor space, so druggability metrics calibrated on that history misclassify many of the signals an exhaustive search returns; genetic association alone is not causality. Targets long thought of as undruggable, including MYC, IRF4, intrinsically disordered proteins, and many protein-protein interaction surfaces, lack the binding-pocket geometry that small-molecule docking models depend on. The literature corpora that knowledge graphs draw from carry publication bias, so novel mechanisms in under-studied areas remain under-represented even when the search is otherwise exhaustive.
In drug design and lead optimisation, the toolkit is mature. Generative models, parallel ADMET scoring, and active-learning loops compress what sequential, labour-intensive work was. Exscientia's Centaur platform produced DSP-1181 for Sumitomo Dainippon Pharma, reaching first-in-human trials twelve months from nomination and screening 350 compounds against the 2,500 typical of conventional approaches; Insilico's Chemistry42 platform produced rentosertib from fewer than 80 synthesised compounds. Cloud-native architecture contributes parallelism and model-serving capacity. The chemistry intelligence depends on model quality and training data; neither is improved by cloud architecture.
At preclinical, the gap between vendor narrative and published evidence widens. Cloud-native architecture earns its place in coordinating the make-and-test loop, where automated synthesis planning, instrument-to-decision data flow, and parallel evaluation compress timelines. Moderna's forty-two-day sequence-to-vaccine-candidate timeline illustrates what platform-enabled coordination delivers for a pre-characterised viral target where the underlying biology was already well-mapped. It does not address the predictive-validity problem Scannell identified as the central driver of Eroom's Law: producing more molecules in vitro, faster, does not improve the translational fidelity of the preclinical models those molecules are tested in.
The LIMS and ELN integration layer is the least-discussed friction at this stage. Instrument outputs in proprietary binary formats and ELN records of variable annotation quality require substantial curation before any model can use them, and the cost gap between organisations that have done that work and those that have not is widest here.
At clinical development, the literature splits cleanly between well-evidenced contributions to trial design and real-world analytics on one side and the attrition record of AI-derived candidates on the other.
Trial Pathfinder's analysis of EHR data from 61,094 advanced lung cancer patients showed AI-driven simulation of inclusion and exclusion criteria could double the eligible patients while improving survival outcomes. Synthetic control arms via digital twins expand experimental arms without proportionally expanding recruitment, and the FDA Sentinel system covers more than 100 million people as the substrate for AI-enabled causal inference methods.
The clinical record is harder to read: the cohort is young, the data is thin, and the early Phase 2 results have not been encouraging. Approximately 70-80 AI-derived molecules are in human trials globally as of early 2026, with the phase distribution heavily front-loaded - 45-50 in Phase 1, 12-15 in Phase 2, three in Phase 3, and none approved anywhere. BCG's Phase 1 success rate of 80-90 per cent shrinks to industry-normal at Phase 2, around 40 per cent. The Phase 2 collapse is what makes the cohort matter analytically; patient heterogeneity, weak preclinical-to-human predictive validity, and incomplete mechanism understanding are the failure modes the field has yet to solve, and rentosertib's 71-patient Phase 2a needs replication while REC-994 and BEN-2293 both missed efficacy endpoints.
At post-market, cloud-native infrastructure is foundational and the stage where regulators are concentrating AI scrutiny. Federated analysis across health systems, continuous ingestion of safety signal data, and integration of EHRs, claims, wearables, and imaging at a population scale all require the architecture that cloud-native platforms provide. The FDA's RWD guidance (2018, updated 2023 and 2025), the EMA reflection paper on AI in the medicinal product lifecycle, the ICH M15 guideline reaching EMA Step 5 in July 2026, and the EU GMP Annex 22 (AI) draft are all anchored to AI use after discovery. The contributions are well-evidenced: pharmacovigilance signal detection at scale, automated adverse event reporting, federated adverse drug event aggregation across hospital networks, manufacturing demand forecasting, and supply chain analytics. The bottleneck is the validation, change-control, and AI-governance overhead that the new FDA CSA guidance, the revised EU GMP Annex 11, and Annex 22 will impose over the next two years.
Platform Readiness and Where Value Concentrates
Procurement processes typically test what a platform can do; they rarely test whether the organisation is ready to deploy it usefully. The diagnostic in Figure 3 separates the two questions, sequencing five structural frictions ordered from the most foundational (data quality) to the most contractual (talent and capability). A "no" at any gate identifies remediation work that must happen before commitment.
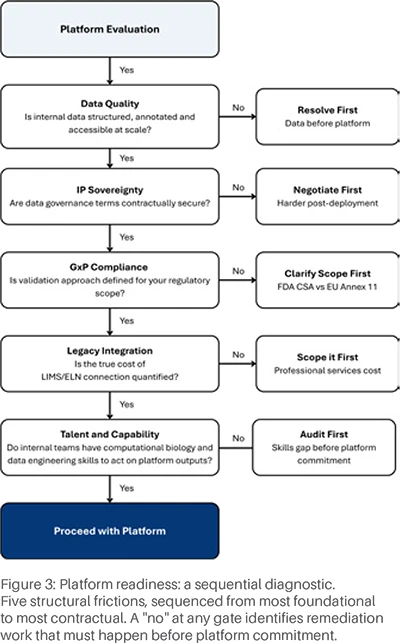
Five structural frictions, sequenced from most foundational to most contractual. A "no" at any gate identifies remediation work that must happen before platform commitment.
Where the platform creates value depends on two variables: data maturity and discovery stage focus. Data maturity is the degree to which internal scientific data is structured, annotated, and accessible at scale. The matrix in Figure 4 maps the four resulting positions. Organisations in the bottom-left quadrant have a data infrastructure problem to solve before platform commitment becomes useful; everywhere else, the matrix indicates the recommended next step.
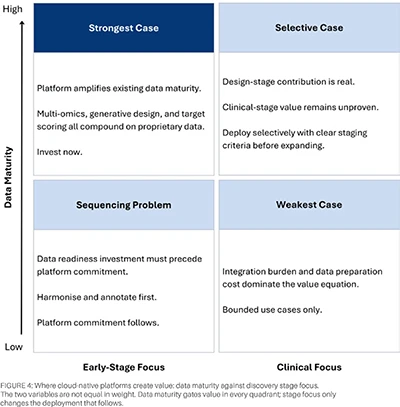
The two variables are not equal in weight. Data maturity gates value in every quadrant; stage focus only changes the deployment that follows.
Readiness gets deferred because the work is unglamorous: harmonising ontologies, annotating instrument outputs, restructuring legacy ELN records, and building data engineering capability are not the line items that win board approval. Platforms are. The diagnostic and the matrix above are intended to make the readiness work as visible to a procurement committee as the platform decision it is meant to precede.
Conclusion
The contribution of cloud-native platforms across the pipeline is uneven: well-evidenced at target identification and post-market, less so at the middle stages, and the clinical case is not yet made. The strategic question for executives is the order of investment, and the answer is the same across organisations of every size: data infrastructure first, platform commitment second, expansion to later stages as the clinical evidence develops. The technology is not the constraint.
REFERENCES
1. PwC. Cloud Business Survey: Pharma and Life Sciences. 2023. https://www.pwc.com/us/en/industries/pharma-life-sciences/cloud-pharmaceuticals-survey.html
2. Recursion Pharmaceuticals. Recursion and Exscientia: Two Leaders in AI Drug Discovery Have Officially Combined. November 2024.
3. Qiu H, et al. Safety and efficacy of rentosertib (ISM001-055) in patients with idiopathic pulmonary fibrosis: a randomised, double-blind, placebo-controlled, phase 2a trial. Nature Medicine. June 2025.
4. US Food and Drug Administration. Computer Software Assurance for Production and Quality System Software. Federal Register. FR Doc. 2025-18468. September 2025.
5. Liu R, Rizzo S, Whipple S, et al. Evaluating eligibility criteria of oncology trials using real-world data and AI. Nature. 2021;592(7855):629-633. doi: 10.1038/s41586-021-03430-5
6. Ren F, Aliper A, Chen J, et al. A small-molecule TNIK inhibitor targets fibrosis in preclinical and clinical models. Nature Biotechnology. 2024. doi: 10.1038/s41587-024-02143-0
7. Abramson J, Adler J, Dunger J, et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature. 2024;630(8016):493-500. doi: 10.1038/s41586-024-07487-w
8. Sumitomo Dainippon Pharma and Exscientia. Sumitomo Dainippon Pharma and Exscientia Joint Development New Drug Candidate Created Using Artificial Intelligence (AI) Begins Clinical Study. 30 January 2020. https://www.sumitomo-pharma.com/news/20200130.html
9. Isomorphic Labs. Isomorphic Labs announces $600 million funding to further develop its next-generation AI drug design engine and advance therapeutic programs into the clinic. PR Newswire, 31 March 2025. https://www.prnewswire.com/news-releases/isomorphic-labs-announces-600-million-funding-to-further-develop-its-next-generation-ai-drug-design-engine-and-advance-therapeutic-programs-into-the-clinic-302415534.html
10. Amazon Web Services. AWS Powers Moderna's Digital Biotechnology Platform to Develop New Class of Vaccines and Therapeutics. 5 August 2020. https://press.aboutamazon.com/news-releases/news-release-details/aws-powers-modernas-digital-biotechnology-platform-develop-new
11. US Food and Drug Administration. FDA's Sentinel Initiative. https://www.fda.gov/safety/fdas-sentinel-initiative
12. Desai RJ, Matheny ME, Johnson K, et al. Broadening the reach of the FDA Sentinel system: A roadmap for integrating electronic health record data in a causal analysis framework. npj Digital Medicine. 2021;4:170. doi: 10.1038/s41746-021-00542-0










